Written by Siva Karuturi, In-Memory Database Specialist Solutions Architect, AWS and Roberto Luna Rojas, Sr. In-Memory Database Specialist Solutions Architect, AWS
Today’s enterprises need to be more agile to improve their customer’s experience, respond to changes quickly, and have the freedom to innovate. As part of their digital transformation journey in the cloud, these businesses need the ability to connect more devices to their applications, faster than ever—from smartphones to connected cars, from manufacturing plants to smart devices in our homes. Therefore, these applications need to scale quickly to potentially millions of users, have global availability, manage large volumes of data, and provide ultra-fast response times for customers.
Developers building modern applications typically need to address several challenges based on user needs, and to plan for the future. User growth is a common KPI (key performance indicator) for businesses as applications mature, needing to support up to millions of new customers and expansion into new regions. Businesses are increasingly analyzing their customers’ usage and behavior to either increase the value of their existing products, or to sell new products. This can result in generating terabytes, or even petabytes of data. Also, as developers plan the application architecture, they need to build flexible, scalable, and cost-efficient workloads. Most of these workloads will need to handle unprecedented levels of throughput and respond in milliseconds—or even microseconds—while sustaining high performance at scale. This influx of data requires developers to have the ability to have flexible data access to model structured, semi-structured, or even unstructured data, and reduce the complexity of their overall architecture. While planning their architecture, developers also need to consider total cost of ownership (TCO) to lower their costs by only paying for what they use without capping how much they can grow.
Developers using a traditional database to build applications requiring low latency and scalability may face critical challenges with speed, scalability, and flexible data access. These challenges include:
- Slow query processing: There are a number of query optimization techniques and schema designs that help boost query performance. However, the data retrieval speed from disk, plus the added query processing times generally results in query response times in double-digit millisecond speeds, at best. This also assumes that you have a steady data load and your database is performing optimally.
- Cost to scale: Whether the data is distributed in a disk-based non-relational database or a vertically-scaled relational database, scaling for extremely high reads can be costly. It can also require several database read replicas to match the performance of a single in-memory cache node’s requests per second. In addition, customers can help boost performance by offloading their frequently accessed queries to a cache and improve overall TCO.
- Need to simplify access to data: Although relational databases provide an excellent and intuitive way to structure data, their data models often don’t match application objects. Due to this mismatch, data access becomes complex and hence lowers performance.
Implementing Database Caching to Improve Performance and Lower TCO
Before implementing database caching, many architects and engineers spend a great deal of effort trying to extract as much performance as they can from their databases. However, there is a limit to the performance you can achieve with a disk-based database, and it can be pointless to try to fix a problem without the right tools. For example, a large portion of the latency of your database query is dictated by the physics of retrieving data from disk.
Database caching can be one of the most effective strategies for improving your overall application performance and reducing your database costs. In a microservices application that may need to retrieve and process data from multiple disparate sources like data stores, legacy systems, or other shared services, latency can range from milliseconds to a few seconds depending on the size of the data and network bandwidth. In these cases, it makes sense to maintain a cache close to the microservices layer to help improve performance. You can cache practically anything that can be queried, where the underlying source of the data could be from relational databases or non-relational databases or even data that can be accessed via an Application Programming Interface (API).
By storing the frequently-read data in a cache, we can reduce the read burden on the primary database, thereby optimally sizing the database and reducing the overall costs. The cache itself can live in three areas—in your database, in the application, or as a standalone layer. The most common database types include database-integrated caches, local or client caches, and remote caches.
Databases such as Amazon Aurora, offer a database-integrated cache that is managed within the database engine and have built-in write-through capabilities. Integrated caches are typically limited to a single node with memory allocated by the database instance. Therefore, data can’t be shared with other instances across nodes, in contrast to the distributed multi-node scalability of Amazon ElastiCache for Redis (up to 500 nodes in a single cluster).
A local cache stores your frequently-used data within your application. This makes data retrieval faster than with other caching architectures because it removes network traffic that is associated with retrieving data. A major disadvantage of a local cache is that among your applications, each application node has its own resident cache working in a disconnected manner. This creates challenges in a distributed environment where most applications use multiple application servers and information sharing is critical to support scalable dynamic environments.
A remote cache (or side cache) is a separate instance dedicated to storing the cached data in-memory. Remote caches are stored on dedicated servers and are typically built on key-value stores, such as Redis and Memcached. They provide hundreds of thousands of requests (up to 1/2 million) per second, per cache node.
The average latency of a server-side request to a remote cache is on a sub-millisecond timescale, which is faster than a request to a disk-based database by an order of magnitude. With remote caches, the cache itself is not directly connected to the database, but is used adjacent to it.
ElastiCache as a Remote Cache
ElastiCache is a fully managed, remote cache that makes it easy to deploy, operate, and scale an in-memory data store in the cloud. The service improves the performance of your applications by allowing you to retrieve information from fast, managed, in-memory data stores, instead of relying entirely on slower disk-based databases. ElastiCache is designed to provide the high availability needed for critical workloads.
ElastiCache offers two fully managed in-memory engines that are compatible with popular open-source technologies, Redis and Memcached. ElastiCache for Redis is a Redis-compatible, in-memory service that delivers the ease-of-use and power of Redis along with the availability, reliability, and performance suitable for the most demanding applications. ElastiCache clusters can scale up to 500 nodes, up to 340 TB of in-memory data, and up to 1PB of total data using the data tiering feature. Data tiering provides a new price-performance option for Redis workloads by utilizing lower-cost solid state drives (SSDs) in each cluster node, in addition to storing data in memory. ElastiCache for Memcached is Memcached-compatible, caching service that will work seamlessly with popular tools that you use with existing Memcached environments.
Caching Patterns and Strategies
Now, let’s take a look at some of the most widely used caching patterns to cache your data.
When you are caching data from your database, there are caching strategies for Redis and Memcached that you can implement. The patterns you choose to implement should be directly related to your caching and application objectives.
Two common approaches are cache-aside or lazy loading, and write-through. A cache-aside cache is updated after the data is requested. A write-through cache is updated immediately when the primary database is updated. With both approaches, the application is essentially managing what data is being cached and for how long.
The following diagram is a typical representation of an architecture that uses a remote distributed cache.

Cache-Aside or Lazy Loading
A cache-aside cache is the most common caching strategy. The fundamental data retrieval logic can be summarized as follows:
- When your application needs to read data from the database, it checks the cache first to determine whether the data is available.
- If the data is available (a cache hit), the cached data is returned, and the response is issued to the caller.
- If the data isn’t available (a cache miss), the database is queried for the data. The cache is then populated with the data that is retrieved from the database, and the data is returned to the caller.

This approach has several advantages:
- The cache contains only data that the application actually requests, which helps keep the cache size cost-efficient.
- The approach is straightforward and produces immediate performance gains, whether you use an application framework that encapsulates lazy loading or your own custom application logic.
A disadvantage to using cache-aside as the only caching pattern is that since the data is loaded into the cache only after a cache miss, high cache miss rates can result in sub-optimal response times.
Using the lazy-loading approach, we can see immediate results for our caching. For example, we loaded a RDBMS table in Amazon RDS for PostgreSQL containing 3.5 million rows of taxi trip data in NYC for March 2022 (available to download here). We used this data to perform queries such as taxi trips for a given date ordered by the pickup time and paginated results 10 by 10.
The SQL query looks as follows:
SELECT * FROM trip WHERE tpep_pickup_datetime BETWEEN '2022-03-01' AND '2022-03-02' ORDER BY tpep_pickup_datetime ASC LIMIT 10 OFFSET 0;
Running this query will take about 1.180 seconds for the first time and 0.992 seconds for subsequent requests, is only saving 0.188 seconds (188 milliseconds). This is not a significant improvement to the query performance.
Now, once we have the data results, we can use ElastiCache for Redis to store this result set for subsequent requests. First, we have to think about a way to consistently fetch the same query, this can be as simple as using a hashing algorithm such as Message Digest Method 5 (MD5).
MD5(“SELECT * FROM trip WHERE tpep_pickup_datetime BETWEEN '2022-03-01' AND '2022-03-02' ORDER BY tpep_pickup_datetime ASC LIMIT 10 OFFSET 0;”)
Hashing the whole SQL query string will yield a value of “aa00331842193b13e2a3dcd06244b808”–a unique string of 32 characters. We can use this to create our Redis Key, with the following format:
query:<md5>
Saving the data into ElastiCache for Redis will be as simple as:
SET query:aa00331842193b13e2a3dcd06244b808 <rdbms_result_set>
If we want to fetch it from ElastiCache for Redis we can do so by using the GET command.
GET query:aa00331842193b13e2a3dcd06244b808
Running this command against ElastiCache will take about 0.000998 seconds (998 microseconds), which results in fetching 4.3KB of data in under 1 millisecond (see graphic below). This provides a significant improvement in query performance—approximately 1,000x faster—as compared to not using ElastiCache.

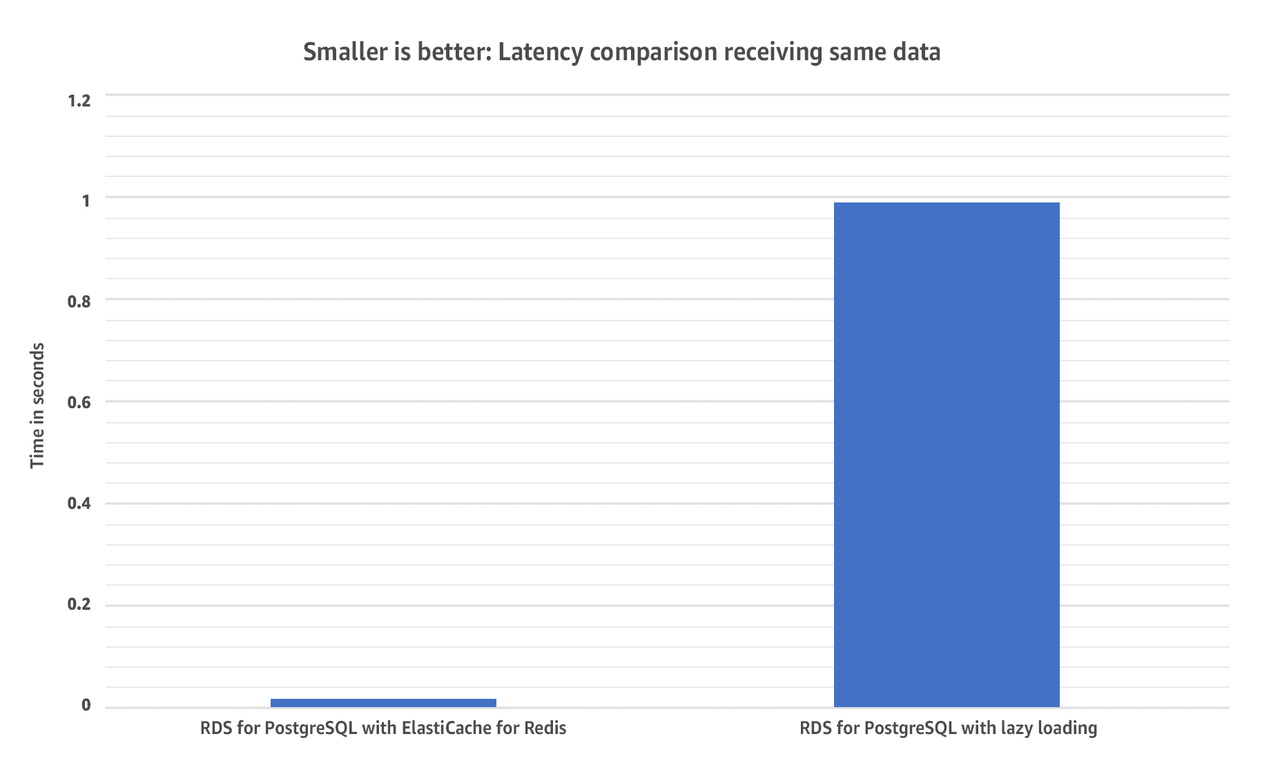
This example demonstrates how ElastiCache for Redis can be used as a distributed cache to reduce latency and improve performance of your workloads.
Write-Through Cache
A write-through cache reverses the order of how the cache is populated. Instead of lazy-loading the data in the cache after a cache miss, the cache is updated immediately following the primary database update. The fundamental data retrieval logic can be summarized as follows:
- The application, batch, or backend process updates the primary database.
- Immediately afterwards, the data is also updated in the cache.

The write-through pattern is often implemented along with lazy loading. If the application gets a cache miss because the data is not present or has expired, the lazy loading pattern is performed to update the cache.
The write-through approach has several advantages:
- Because the cache is up-to-date with the primary database, there is a much greater likelihood that the data will be found in the cache. This, in turn, results in better overall application performance and user experience.
- The performance of your database is optimal because fewer database reads are performed.
A disadvantage of the write-through approach is that infrequently-requested data is also written to the cache, resulting in a larger and more expensive cache.
A proper caching strategy includes effective use of both write-through and lazy loading of your data and setting an appropriate expiration for the data to keep it relevant and lean.
Conclusion
Modern applications can’t afford to have poor performance. Today’s users have low tolerance for slow-running applications and poor user experiences. When low latency and scaling databases are critical to the success of your applications, it’s imperative that you use database caching.
ElastiCache is a fully managed, in-memory caching service supporting flexible, real-time use cases. You can use ElastiCache for caching, which accelerates application and database performance, or as a primary data store for use cases that don't require durability like session stores, gaming leaderboards, streaming, and analytics. ElastiCache is compatible with Redis and Memcached.
Get Started for Free with ElastiCache
AWS Free Tier
ElastiCache is part of the AWS Free Tier. Upon signup, new AWS customers receive 750 hours of ElastiCache cache.t2.micro or cache.t3.micro node usage for free, for up to 12 months. The AWS Free Tier applies to participating services within AWS Regions around the world. Your free usage under the AWS Free Tier is calculated each month across all regions and automatically applied to your bill—unused monthly usage will not rollover to future months. For more details, see the AWS Free Tier FAQs.
To learn more about ElastiCache, visit the ElastiCache product page, ElastiCache technical documentation, or read recent blog posts about ElastiCache on the AWS Database blog.